How to use the AWS lambda function as a thumbnail generator
You can use the aws lambda as an automatic thumbnail generator, when you are uploading images to aws s3 bucket. Let's see how simple is to do a function like this.
What is an AWS S3 Bucket ?
AWS S3 is a service of amazon web services. AWS is an abbreviation for Amazon Web Services and S3 stands for Simple Storage Service. The service offers developers and companies to store their data on remote servers and access them from anywhere in the world.
The simplest way to describe the service is that it offers a way for anyone to store data on servers that can be accessed over the internet in much the same way as storing files in a datacenter.
AWS S3 is a storage service in the cloud that developers can use to store data in the cloud. It offers storage for any amount of data from 5 GB to exabytes, meaning you can use it to store anything from a few files to an unlimited number of photos and videos.
A bucket is a storage location on AWS S3 servers. AWS offers buckets in three different storage classes: Standard, Standard IA, and Reduced Redundancy.
The standard bucket costs $0.023 per gigabyte per month, the Standard IA bucket costs $0.0125 per gigabyte per month, and the Reduced Redundancy bucket costs $0.008 per gigabyte each month (with a limit of 5TB).
The AWS S3 bucket is the container where your file sits. A bucket is a logical grouping of related objects that lets you organize objects into an hierarchical collection that shares a single namespace. The name of your bucket must be globally unique across all AWS customers, so be sure to come up with something original!
A Bucket can store three different types of items: objects, folders and bucket properties. Objects are the files that we upload to Amazon S3 and folders are containers for organizing objects in our buckets. Bucket properties contain information about our buckets such as the last time we accessed it or how much data it contains.
The main workflow for the automatic thumbnail creator
The basic workflow will be the following:
- the (any) application will upload the image file to the S3 bucket
- the aws s3 will automatically trigger the AWS Lambda function
- The lambda function will read the image file, resize it, and will save it to a different bucket
To achive the resize we need a 3rd party external library,
Let's start with the Visual Studio AWS Lambda template
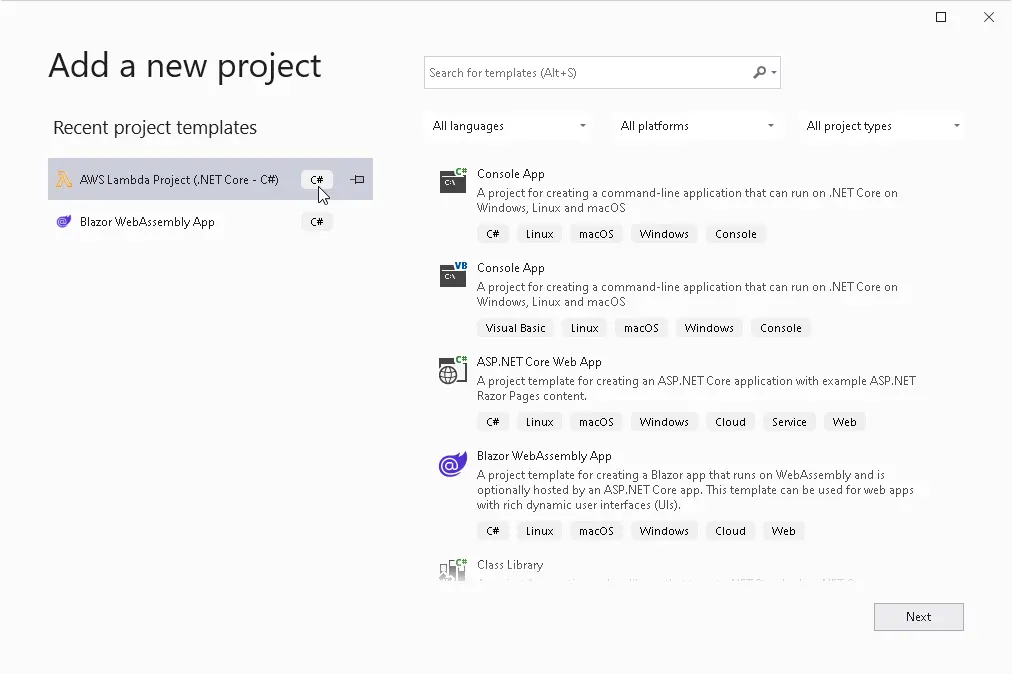
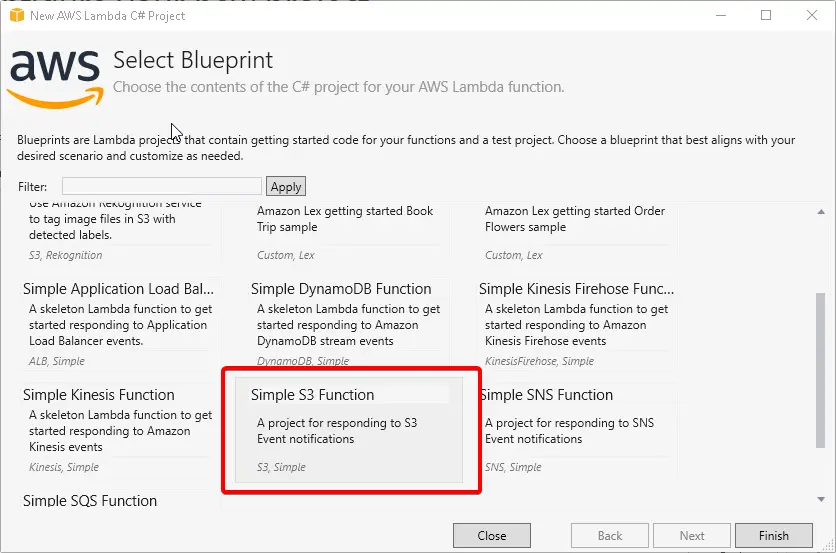
After this, visual studio will present you a very nice aws lambda code from the template, which can read from the aws s3 storage bucket by the upload trigger.
/// /// This method is called for every Lambda invocation. This method takes in an S3 event object and can be used /// to respond to S3 notifications. public async Task<string> FunctionHandler(S3Event evnt, ILambdaContext context) { var s3Event = evnt.Records?[0].S3; if(s3Event == null) { return null; } try { context.Logger.LogLine($"Trying to Get object {s3Event.Object.Key} from bucket {s3Event.Bucket.Name}."); var response = await this.S3Client.GetObjectMetadataAsync(s3Event.Bucket.Name, s3Event.Object.Key); context.Logger.LogLine($"Get object {s3Event.Object.Key} from bucket {s3Event.Bucket.Name}."); return response.Headers.ContentType; } catch(Exception e) { context.Logger.LogLine($"Error getting object {s3Event.Object.Key} from bucket {s3Event.Bucket.Name}. Make sure they exist and your bucket is in the same region as this function."); context.Logger.LogLine(e.Message); context.Logger.LogLine(e.StackTrace); throw; } }
For testing purpose, upload this code, and connect it with a trigger to an aws s3 bucket, try to upload an image file, and after the upload, please check the aws cloudwatch log, there must be traces of the application.
Add trigger to the aws lambda function

Set the lambda trigger configuration, set your aws s3 bucket name (of course, you need to create one before the trigger config), and you can set some additional properties, like prefix - suffix, and you can select what kind of event will be sent to your serverless aws lambda function.

Avoid recursion !
On the configuration screen, the aws console will warn you about the possible recursion, if you are writing the output to the same bucket, the lambda function will be triggered again and again, that will cost you mouch money. The solution is simple to avoid this, just use a different bucket for writing then the source bucket.
What is a recursion ?
A recursive function is a function that calls itself. Recursion is the process of solving a problem by breaking it down into smaller problems that are similar to the original problem.
The recursive nature of this function can cause an endless loop if it is not properly coded. To avoid this, one should be aware of the maximum number of iterations they want to allow for their code before they start writing it.
Why you need logging ?
Logs are a crucial part of any application. Logs provide information about the state of the application and its environment, such as errors, crashes, and warnings. They also monitor the performance of your application and can help you identify anomalies that might indicate a problem with your system.
Cloudwatch is a monitoring service that lets you monitor and log metrics from AWS services like EC2, ECS, RDS and many more. It also gives you insights into how to improve your applications performance by giving you detailed logs on how they are performing on AWS services.
If you check the cloudwatch log, you can see a new entry on the log, which will contain the information, what was provided by your code
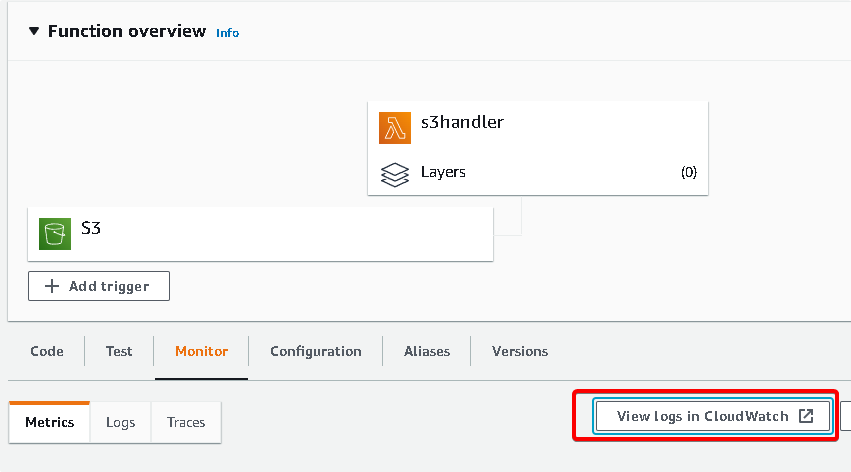

If you are facing some kind of error in the cloudwatch log, please verify this:

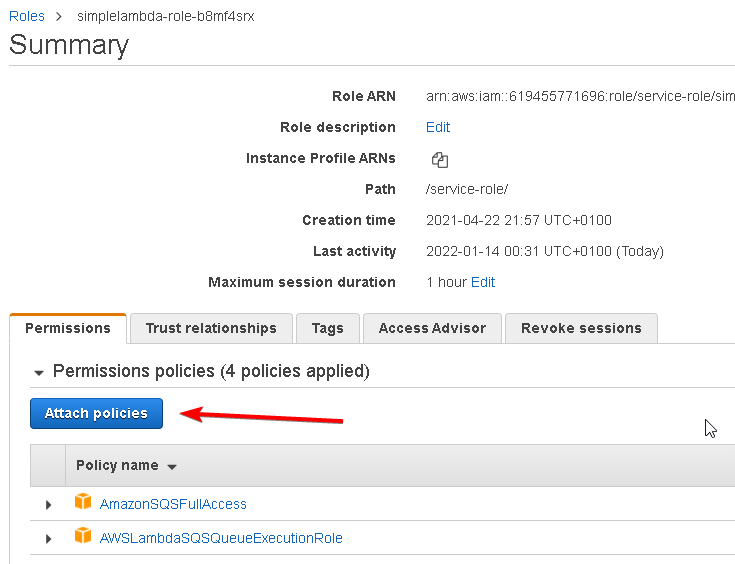
The aws lambda function must have permission to read from the aws s3 bucket, to configue this, goto the lamda config tab, select permission, and click on the actual execution role
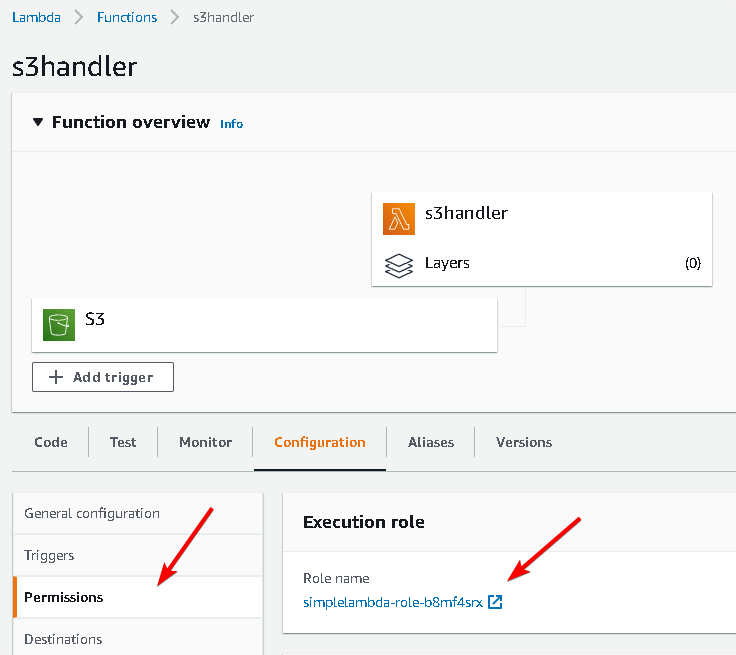
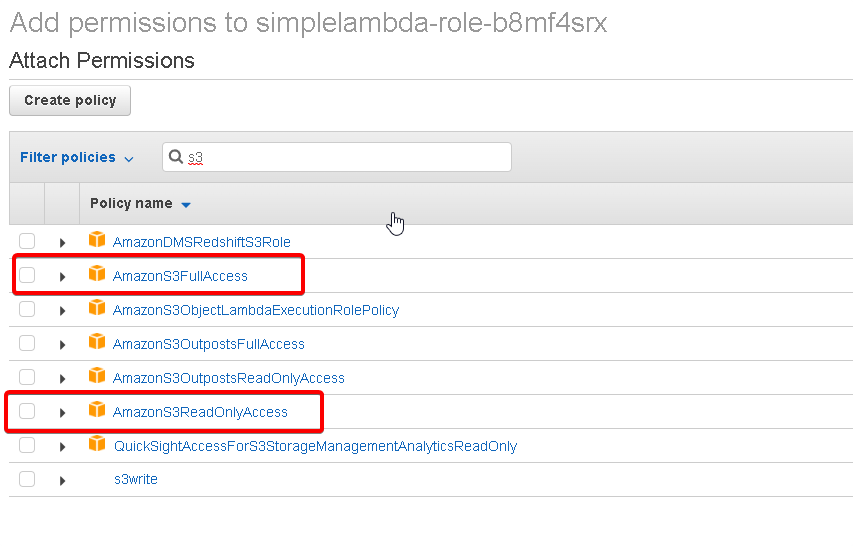
At the role editor screen, "Attach policy", and on the policy search screen, search for "S3", and you can choose the aws readonly permission for this demo, but later you need write permission also, so choose the aws full access permisson, just remember, during other project if you need to read only from the bucket, then use the s3 readonly access permission, as a general rule, you always need to use the lowest permission.
So our basic function is working, now we can move forward to the image processing functionality.
For the image processing we need a thrid-party library, so can find many of them, i chose imagemagick, you can get it easily from a nuget package, just goto the solution explorer, right click on the project, and select nuget package manager.
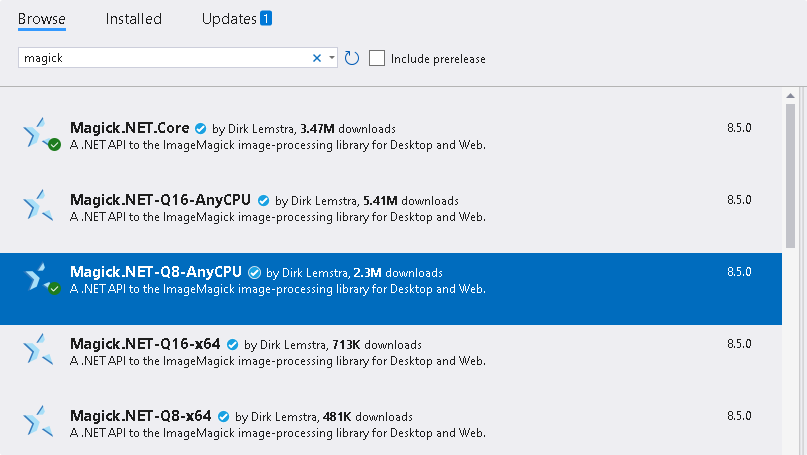
When you have the image processing library , we can start the real work on the image.
Let resize the picture
Go and read the s3 object from the bucket with a stream, and you can use that stream directly, to create the image collection for the resize.
After the resize, just use the image write function, for output we can use a stream, in this case a memory stream is perfect as we don't need the results later, and the s3 putpubject can work from the stream directly.
// let's get the s3 object from the bucket, we have the bucket name and the object key in the event parameter using (GetObjectResponse response = await S3Client.GetObjectAsync(s3Event.Bucket.Name, s3Event.Object.Key)) { using (Stream responseStream = response.ResponseStream) { using (StreamReader reader = new StreamReader(responseStream)) { string contentType = response.Headers["Content-Type"]; Console.WriteLine("Content type: {0}", contentType); context.Logger.LogLine($"Get object {s3Event.Object.Key} from bucket {s3Event.Bucket.Name}."); if (s3Event.Object.Key.EndsWith(".jpg")) // you can do any kind of filtering, or remove the condition, and process everything { // Read from the s3 stream using (var collection = new MagickImageCollection(responseStream)) { foreach (var image in collection) { image.Resize(200, 0); // let resize with keep aspect ratio option, the height will be automatically calculated using (MemoryStream memStream = new MemoryStream()) { image.Write(memStream); // let write the resized image to the target bucket with the same name var outFileName = s3Event.Object.Key; // you can change/manipulate the output filename here if you want to pre/postfix it await S3Client.PutObjectAsync(new PutObjectRequest() { Key = outFileName, BucketName = BucketName, InputStream = memStream }); } } } return response.Headers.ContentType; } } } }
And you did it!
The resizing is working, the image output will be in the target bucket, you can use it for thumbnail in your web application.
Conclusion
The serveless AWS lambda function is suitable for many different use cases, as it has a lot of different input trigger, reacting on aws s3 bucket events is very easy. Creating an automatic thumbnail creator is pretty straightforward, you need to spend half on hour and you are ready to go.